Lets understand the background first, what is KEXEC? It is a fastboot mechanism that allows booting the linux kernel from the context of an already running kernel without going through the BIOS. Undoubtedly, the BIOS checks at start-up is time consuming as it runs POST (Power On Self test) and initializes the basic hardware devices like CPU, RAM, Storage Card, DMA controllers. So, using kexec can save a lot of time with quick reboot.
Kdump is something which follow this mechanism of fastboot. It is a crash dumping mechanism which utilizes kexec. The crash dumps are generated from the context of a freshly booted kernel, not from the context of crashed kernel. Kdump uses kexec to boot into a second kernel whenever system crashes. This is also called as capture kernel and it boots with a very little memory and capture the dump image.
Using kdump allows booting the capture kernel with out going through BIOS hence the contents of the first kernel’s memory are preserved, which is essentially the kernel crash dump.
How to install kdump is in this article.
System becomes unresponsive with message “INFO: task <process>:<pid> blocked for more than 120 seconds”.Issue:
/var/log/messages had a series of following messages before the system became unresponsive:
INFO: task <process>:<pid> blocked for more than 120 seconds
Reasons:
Now it could be due to System facing memory or disk congestion and therefore process are being starved of available resources.
This could be just a warning that something not working optimally. Blocked process may eventually process when the system recovers.
Diagnosis:
- Check for the hung tasks (tasks that are stalled with D state, uninterruptible. A task is waiting for resource, could be completion of pending IO, or other types of resources like locks or file system transactions may result the process being stuck in D states for a longer period of time). Now the question may arise related to stalled task or hung task. Stalled task will eventually exit D state and continue processing, whereas a truly hung task may not leave the D state. Therefor, we are using the parameter, hung_task_timeout_secs to separate normal stalled task or hung task. Basically, after this interval a normal stalled task will be considered as hung task. Now, troubleshooting beyond this scenario would require to engage Redhat Support.
- Check the currently set configuration for blocked task configuration.
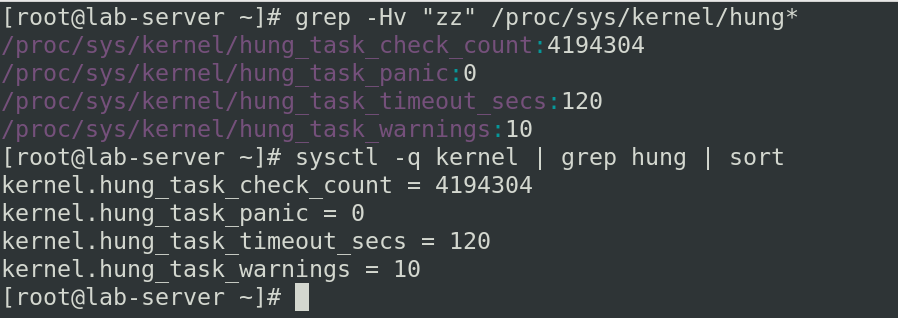
- hung_task_check_count: Maximum count of processes to check. In case there are more processes than this number? Not all processes will be checked for stalled, blocked, state.
41,94,304 is the default value. If current number of processes exceeds this? Only the first 4+ millions currently existing processes will be checked.
- hung_task_timeout_secs: It checks the interval. Default value is 120, if a process is blocked for more than 120 secs, a warning will be issued. To disable, just set the value to 0.
INFO: task <process>:<pid> blocked for more than 120 seconds
- hung_task_panic: This parameter will decide whether to panic on tasks that are blocked for more than the hung_task_timeouts_secs value. If this is set to 1, instead of warning, the system will panic whenever the blocked task is detected. If you want to troubleshoot and want to generate vmcore when this event generated, set it to 1.
- hung_task_warning: Maximum number of warnings. After this many warnings issued, no more will be shown until reboot. Default value is 0.
